(I will try to use the terminology adapted from the original OSC 1.1 definition, with additions from OSCQuery where these make sense. I’ve only taken the liberty to use the term Namespace instead of OSC Address Space, as it is less clunky to use repeatedly in the text).
In several OSC enabled applications, the Namespace (OSC Address Space) is very large, and can comprise a tree-structure hierarchy with obvious repetition. Below is an example from Resolume Arena, of the main elements where repetition occurs:
- /
- /composition
- /composition/columns
- /composition/columns/n (1 – 9)
- /composition/layers
- /composition/layers/n (1 – 3)
- /composition/layers/n/clips
- /composition/layers/n/clips/n (1 – 9)
- /composition/layers/n/video
- /composition/selectedclip
- /composition/selectedlayer
- Etc.
Columns, Layers and Clips, each have complex sub-Namespaces, which repeat multiple times in the above.
Even without repetition, often logical separation and sub-groupings is desirable - e.g. the root, and Composition, in the above example.
I’ve chosen to refer to each specific sub-Namespace ‘type’ as Class in this text for the time being.
I’ve also chosen the name Address, for an actual Instance of such a Class - different from “just” the Namespace, because it is paired with a state for all its values, and an (IP/Port) Location.
Suggestion
I propose the introduction of two new OSC Query Attributes: CLASS, and INACTIVE, to allow the unambiguous description of such structures - the reasoning for this is presented below.
Note I write here to ask for feedback - if you can suggest a better way than using two new Attributes I’d be very glad to hear how!
Context
All of the suggestions I provide for OSC Query, are for allowing the control of an OSC Server by an OSC Client that is simultaneously using and aware of the entire Namespace.
This is atypical, and I’d love to be proven wrong, but the only application doing this fully I am aware of is TWO – all other timeline/control applications, require the use of each individual OSC Message explicitly, and do not support working with groups/subtrees of OSC Containers & Messages.
I’m convinced though it is “the way of the future”, to enable OSC Clients to manage the increasing complexity of OSC Servers.
Why this distinction of sub-Namespaces (class) is desirable
Beyond the potential avoidance of superfluous repetition, identifying which sub-Namespaces are instances of the same Class which have the same interface, e.g. Resolume Clip, allows their optimal treatment for example in the GUI of an OSC controller application.
The same goes for identifying which principal groupings are desired, beyond only where repetition occurs.
In the below image is an example: Three light Fixtures in MadMapper, which, because they are identified as separate instances of the same Class, can each get a dedicated panel in an automatically generated GUI.
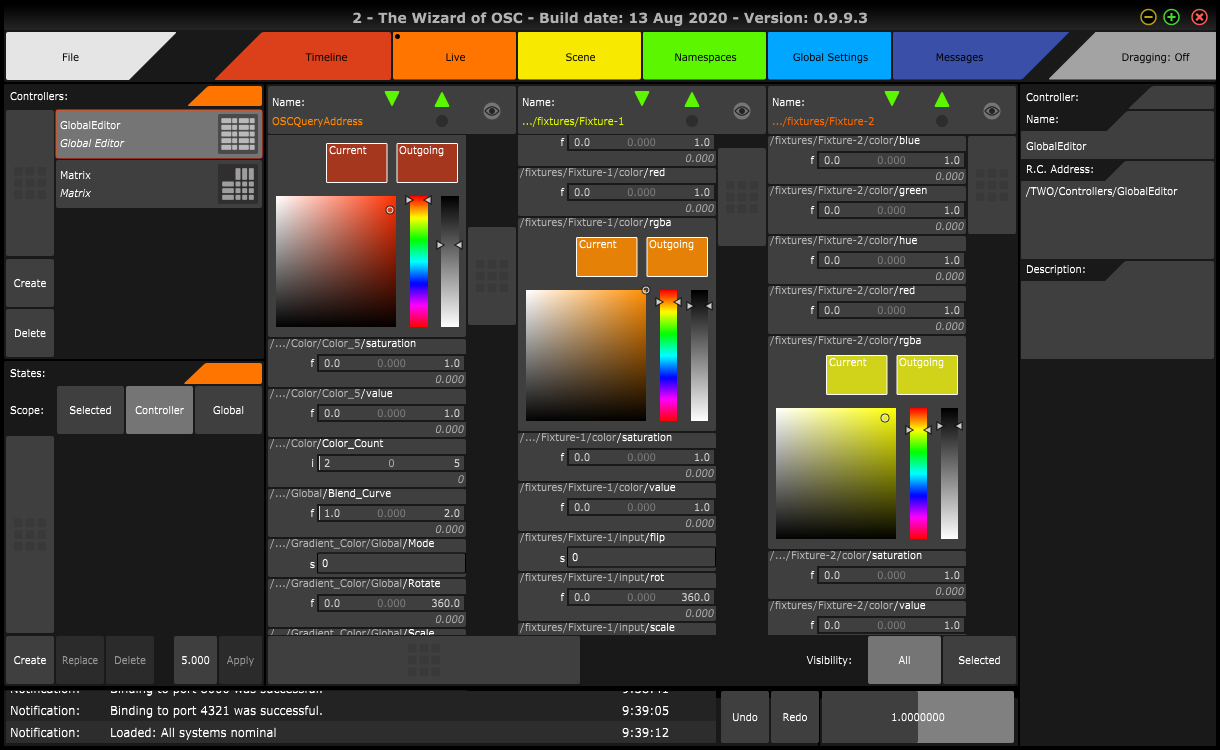
Moreover, a pre-set stored for one, can then easily be applied to the others, since it is known they conform to the same Class.
Another example - In the Resolume Arena Namespace, each Layer has several clips. When each Clip is selected in the tree, a panel with its specific properties are displayed. This helps navigate and use an otherwise extremely large OSC Namespace.
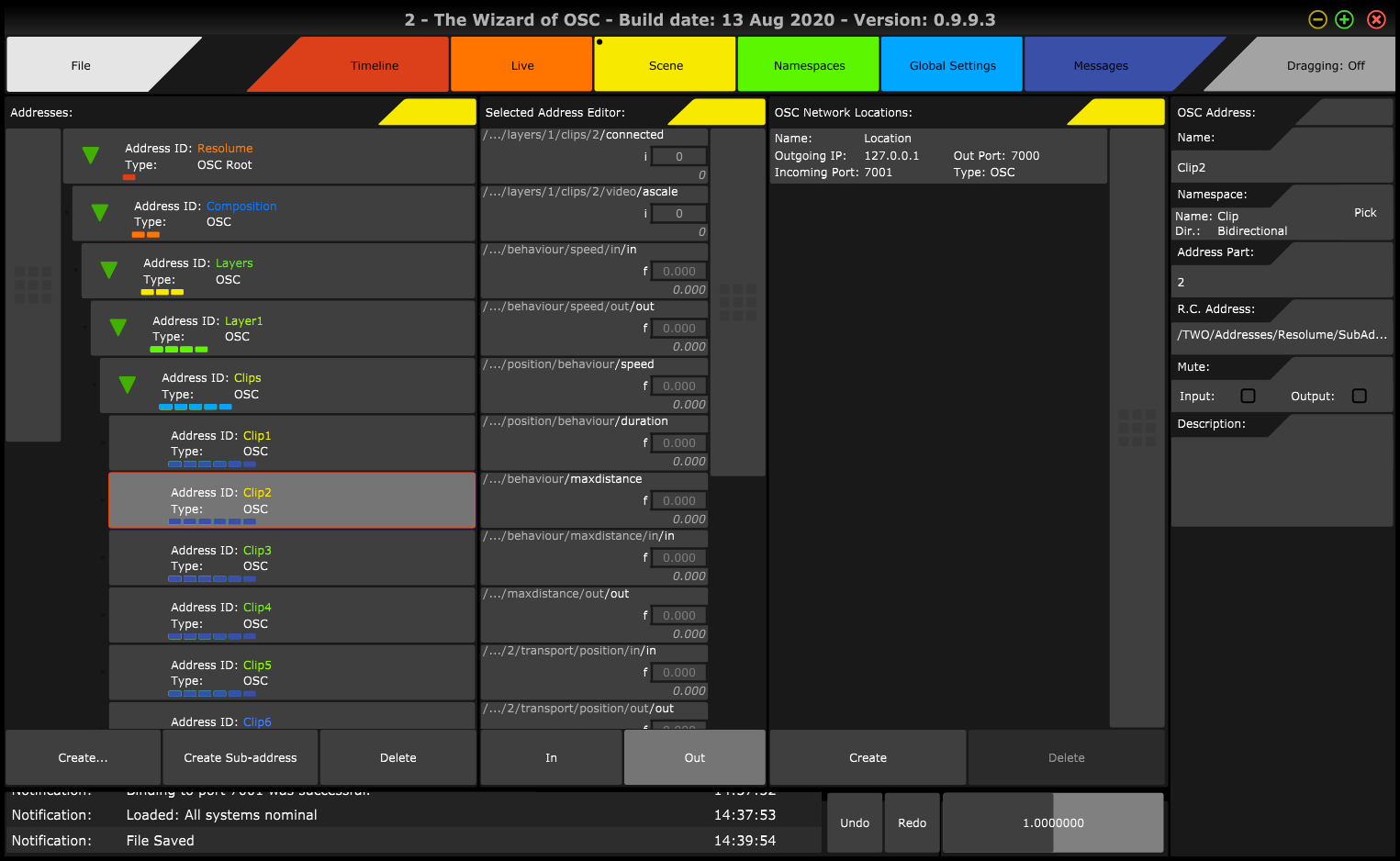
Also, the root Resolume Class, while not repeated, is usefully treated separately from the rest, just as the Class Composition.
When recording into timelines: by simply arming selected instances such Classes for recording, all messages received specifically for each armed Address instance, is recorded into a recording lane dedicated to it.
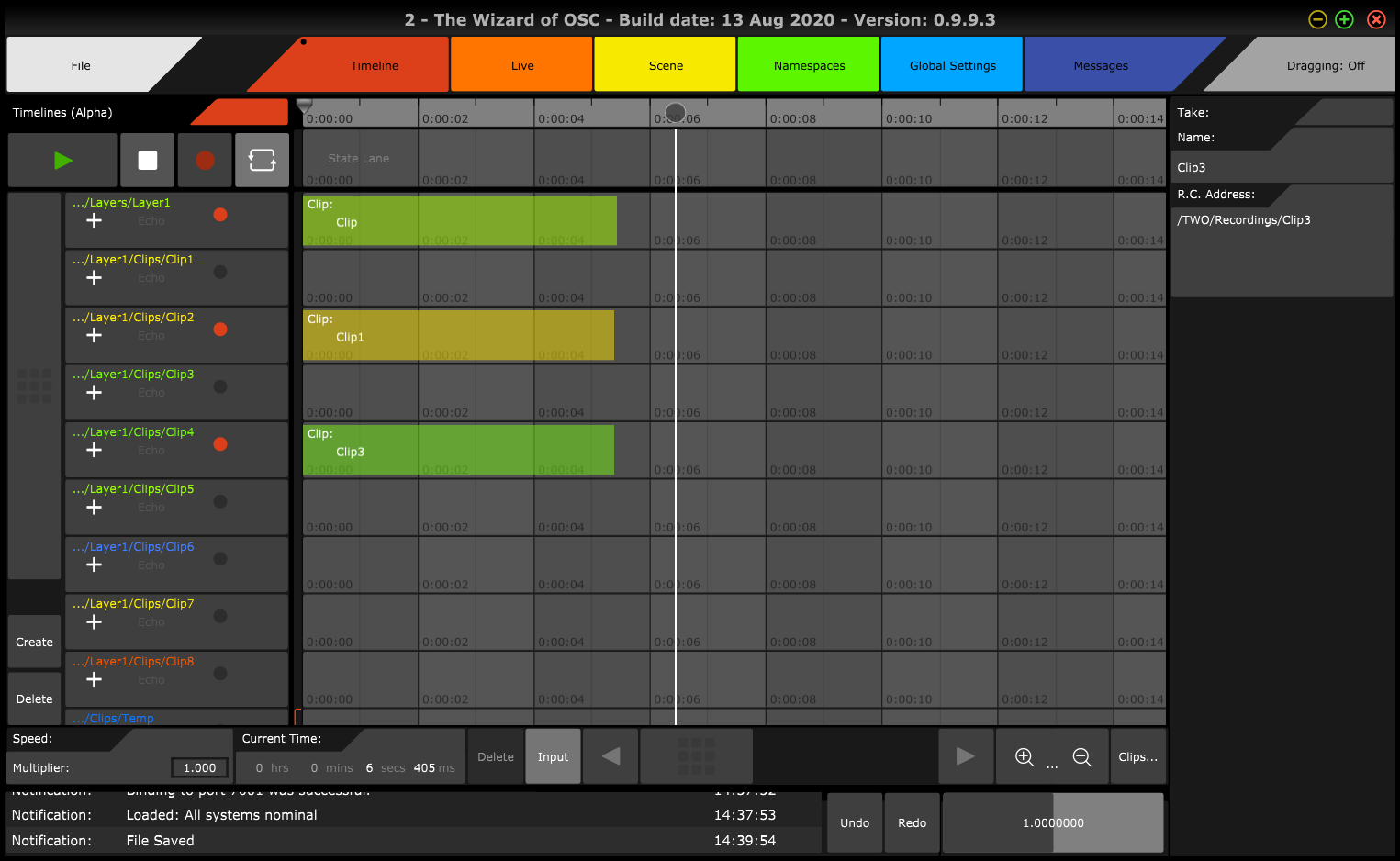
Currently in OSC Query and other discovery protocols, there is some provision for describing such hierarchies.
For use cases such as the above, there needs to be a robust mechanism to identify which sub-Namespaces are identical, so that they can be defined as Classes, and which not - for example when copying a recorded clip of messages from one target to another, where it is needed to then know that they conform to the same Namespace.
Current existing mechanisms, and their relative shortcomings
In the Ossia library there is a mechanism where a node communicates the bounds of the instances it can contain: “Instance Bounds” (ossia terminology in italics).
If min==max==0, it contains no instances. Otherwise, any sub-node can be treated as an instance. For example, columns, layers, and clips in Resolume. Or fixtures in the MadMapper Namespace.
This is imperfect, primarily because it doesn’t cover the use case of instances of the same Class/type also elsewhere in the hierarchy – e.g. that /someothershapes/othercircle1, is of the same Class as /shapes/circle1.
Moreover, just as in the analogous .1-.n notation of libossia’s OSC Query implementation, the node can only hold instances, not a mixed sub-hierarchy. e.g., /shapes/cicle1, shapes/circle2, shapes/square1, shapes/square2, for example. It also forces nodes to share a name, which may not be user-friendly, as uses are likely to want to name each instance with something more descriptive than circle.1 and circle.2.
Also, the ‘.’ notation risks breaking / confusing the interpretation of OSC 1.x legacy namespaces, which too might have chosen to use ‘.’ - fully permitted - in node names.
Not as importantly but still noteworthy is that Namespaces of complex applications grow very-very large, where often the size is due to repetition, e.g. when for each MadMapper fixture, all of its sub-Namespace is repeated, per instance.
The TWO software implements a solution to these points.
Instead of treating an application as having one big Namespace, in TWO the big Namespace can be split into several Namespaces, which between them have no defined relation. These can then be assembled into a separate tree-structure of “Addresses” in TWO - where a “Root Address” is a combination of a Namespace and IP/Port “Location”, and which can then have several sub-addresses, each of which can have its own OSC “Address Part”, and an optional Namespace, thus re-assembing the full OSC server’s Namespace, this time with the distinction of which Class appears where.
So for example, the above Resolume hierarchy, becomes the separate Namespaces of:
- Layer
- Clip
- Column
- Composition
- Resolume
To represent the full Namespace of Resolume through this model, the following Address hierarchy is created (Class in {} brackets):
- Resolume {Resolume}
- Composition {Composition}
- Layers {null}
- Layer1 {Layer}
- Clips {null}
- Clip1- Clip9 {Clip}
- Temp {Clip}
- Clips {null}
- Layer2 (>>>)
- Layer1 {Layer}
- Columns {null}
- Column1 – Column9 {Column}
- selectedClip {Clip}
- selectedLayer {Layer}
- Layers {null}
- Composition {Composition}
(The Root Address “Resolume” should have Namespace Resolume. “Layer1” etc and “selectedLayer” should have Namespace Layer. Clip1 through Clip9, and selectedClip, should be of Namespace Clip. Column1 through Column9, Namespace Column. Finally “Composition” should be of Namespace Composition. ”Layers”, “Clips”, “Columns”, should all not have a Namespace assigned at all, only an OSC Address Part, as they only serve for grouping).
This solution in TWO however doesn’t currently have any automatic discovery support, but requires manual setup by the end-user.
Since the purpose of this text isn’t to explain how TWO works in detail I’ll leave that part out. If you want to try the above, the creation and use of such a structure with Resolume, along with example .two files, is available here.
Finally, see below, just to illustrate the above in TWO screenshots:
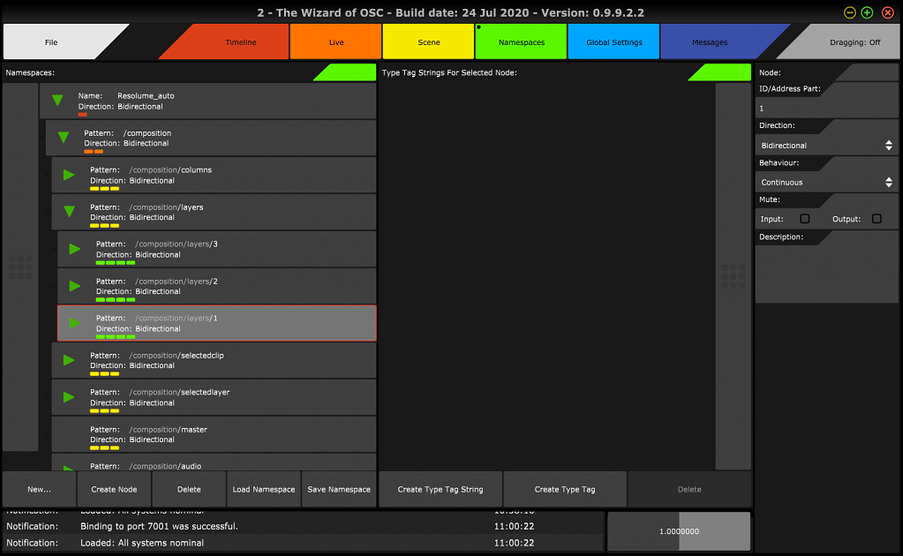
Before: One Big Namespace
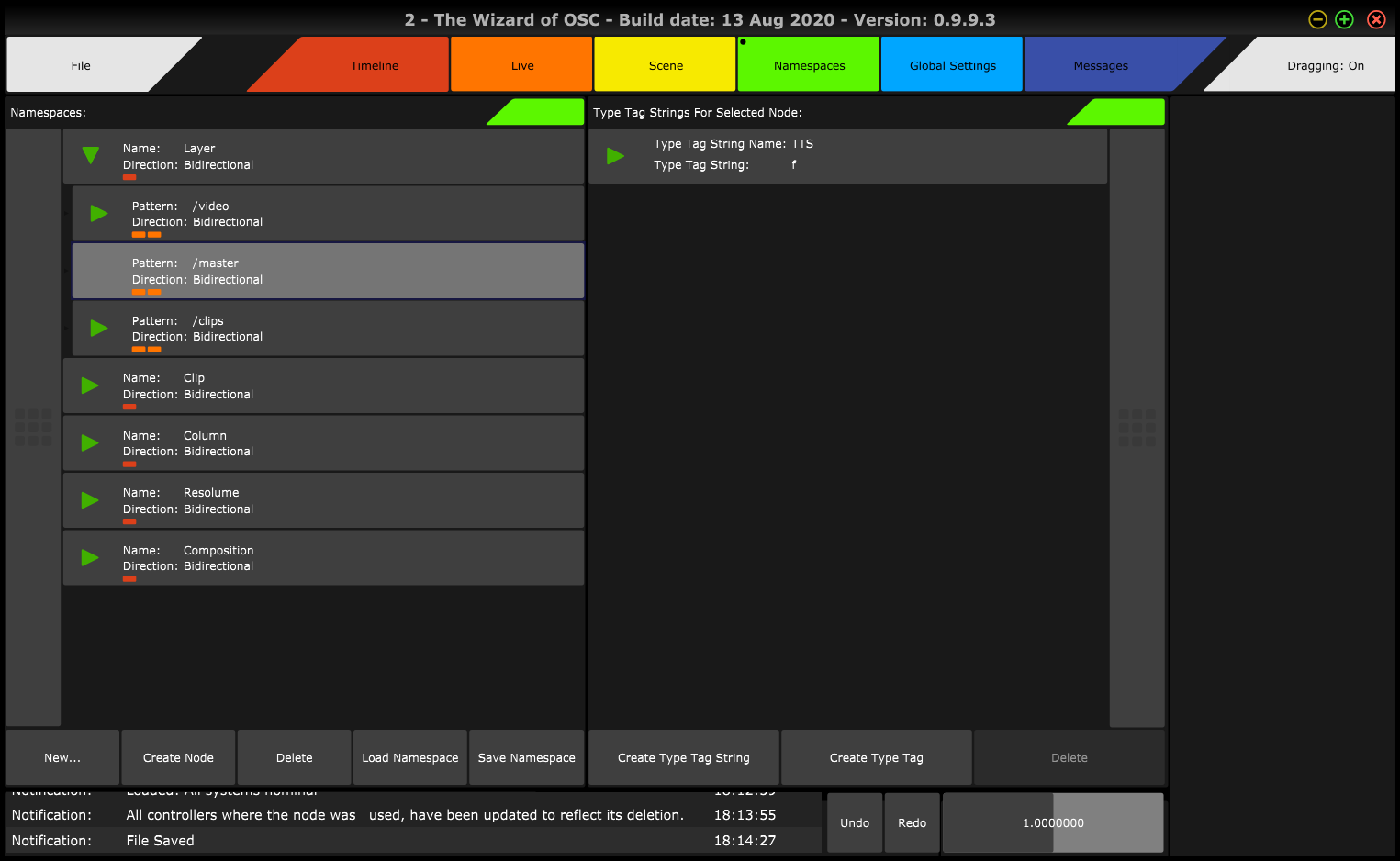
After: Many Separate Namespaces…
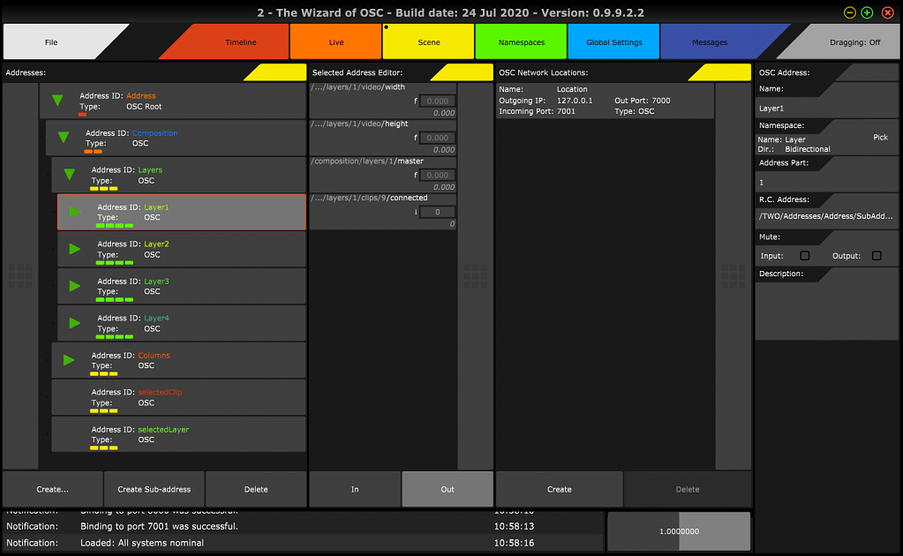
…and an Address hierarchy linking them together.
Now to the interesting part - how can the above be made compatible with OSC Query Namespace discovery?
Discovery of Namespace & Address Hierarchies
“Namespace”, “Class” and “Address” as names stay as placeholders, but I’d be more than happy for suggestions, and would then gladly change these also in TWO.
I don’t see how the EXTENDED_TYPE Attribute of OSC Query can be used to solve this.
Instead I propose the introduction of a new Attribute: CLASS.
Idea: Attributes CLASS (and INACTIVE)
(Alternatively OSC Query TAG’s such as “Class:Fixture”, or “Class=Fixture”).
The first time a Class appears, is the first time CLASS is used. The subsequent appearances imply that the sub-namespace is identical, except only for state-dependent values, e.g. the current VALUE Attribute of an OSC method.
Multiple inheritance(?) should be disallowed, i.,e. No more than one CLASS.
OSC Containers, e.g. Layers, Clips, Columns in Resolume, have to specify a CLASS “null”, and still have an OSC address path.
INACTIVE only makes sense for sub-nodes of the node labelled with CLASS, to signpost which are INACTIVE.
For example, CLASS “Shape” can have subnodes that are OSC Messages diameter “f”, and edge_count, “i”. A particular instance can have diameter, because it is a circle, but then edge_count is INACTIVE. Vice versa, a polygon has an edge_count, but then diameter is INACTIVE. Then the rest of their parameters. such as position, bounding box, colour, etc, can all be common.
While verbose, I think it could help allow OSC Server domain models that have sub-classing, without transmitting the entire class hierarchy simply for the purpose of OSC Namespace specification for message passing.
This model can also be used in combination with the Server->Client PATH_CHANGED, PATH_RENAMED, PATH_ADDED messages of OSC Query, and even more so possible equivalent Client->Server commands to create/rename/remove nodes, to use the libossia term. It signposts which node Classes are receptive to such requests.
Question to you:
Optionally, from the appearance of the CLASS Attribute and down in the Json, all sub-attributes could be omitted, for all second appearances of a CLASS. So the first specification of CLASS Fixture is complete, but subsequent are sparse, assuming all data is then the same as that first appearance. Then, sub-attributes can optionally be specified, in the case where their value is different to when the first instance appeared, for example when VALUE is not the same.
The only real benefit would be to reduce the size of the Json file.
Variations due to sub-classing etc in the namespace, could be catered for using this new INACTIVE Attribute, where an OSC Method can either be active or not, depending on what the particular instance supports. As an example of how this will be used, INACTIVE OSC Methods will appear in the Namespace, but not when they are instantiated in an Address of TWO.
(The INACTIVE Attribute could also be used in other cases, where multiple OSC Methods in a namespace have the same target in the software, and only one should be used, e.g. /rgb, or /hsv for colour - see this topic).
Discussion
I find this proposal solves many of the problems with large OSC Namespaces with little overhead, and maintaining compatibility both with the original OSC spec, and OSC Query.
It, most crucially, does so without imposing any restrictions on the use of the original OSC 1.1 spec.
As it is, my above proposal only details requesting the full Namespaces, but that is for the sake of brevity. It seems straightforward for it to be extended so that only a single sub-Namespace can be requested for example, or so that sub-addresses are created and deleted, essentially using the already defined optional Attributes of OSC Query for dynamic Namespace manipulation and querying.
None that this idea has evolved from an earlier solution conceived and described in this post. It wasn’t as good a solution, mainly because it disallows having different VALUE Attributes for OSC Messages of the same CLASS, instantiated in different locations of the full Namespace.
Let me know what you think in the thread below!